Dbs101_flippedclass6
Topic : Advantages, Disadvantages and Applications of types of Nonrelational Databases
Non-relational databases, also known as NoSQL databases, offer various advantages, dangers, and programs that set them other than conventional relational databases. Understanding these elements is critical for making knowledgeable decisions whilst deciding on the right kind of database for unique use cases.
Advantages of Non-Relational Databases
Scalability: Non-relational databases excel in coping with big amounts of statistics across multiple servers or nodes with out compromising velocity or availability four.
Flexibility: These databases do not follow a set schema, bearing in mind the garage and processing of various types of records without requiring schema adjustments or migrations.
Performance: Non-relational databases can provide faster overall performance for specific use instances, which includes large information and actual-time processing.
Development Speed: The flexibility and adaptableness of non-relational databases allow faster development and innovation, as builders can test and iterate with facts fashions and features with out affecting existing information.
Variety of Data Types: NoSQL databases can keep a huge range of records types, consisting of unstructured, based, or semi-dependent statistics, making them versatile for numerous packages.
Disadvantages of Non-Relational Databases
Data Consistency: Non-relational databases can also compromise information consistency and reliability, as they do now not implement rules and constraints that make certain statistics validity and integrity.
Complexity: Administration of NoSQL databases can be more complex because of the imprecise statistics shape, making tasks like shifting statistics to strongly typed programming languages challenging.
Limited Query Support: Non-relational databases may not guide superior queries and operations, together with joining, filtering, aggregating, and sorting data from a couple of sources, proscribing statistics evaluation and manipulation competencies.
Applications of Non-Relational Databases
Unstructured Data: Non-relational databases are ideal for storing and processing huge quantities of unstructured records, including pix, films, files, or JSON files.
Social Media and Analytics: Applications with various information sorts that require managing various facts structures can gain from the use of NoSQL databases, making them suitable for social media systems and analytics software.
Highly Scalable Systems: Non-relational databases are highly scalable and might efficiently take care of huge-scale, dispensed facts, making them appropriate for applications with high study/write loads and big datasets.
Fast Development and Innovation: The flexibility of non-relational databases allows for quicker development and innovation, making them a favored preference for applications that require rapid iterations and experimentation with information fashions.
In essence, SQL databases are like spreadsheets with rows and columns, while NoSQL databases are more like a mix of different data types and structures, making them more adaptable to various data needs.
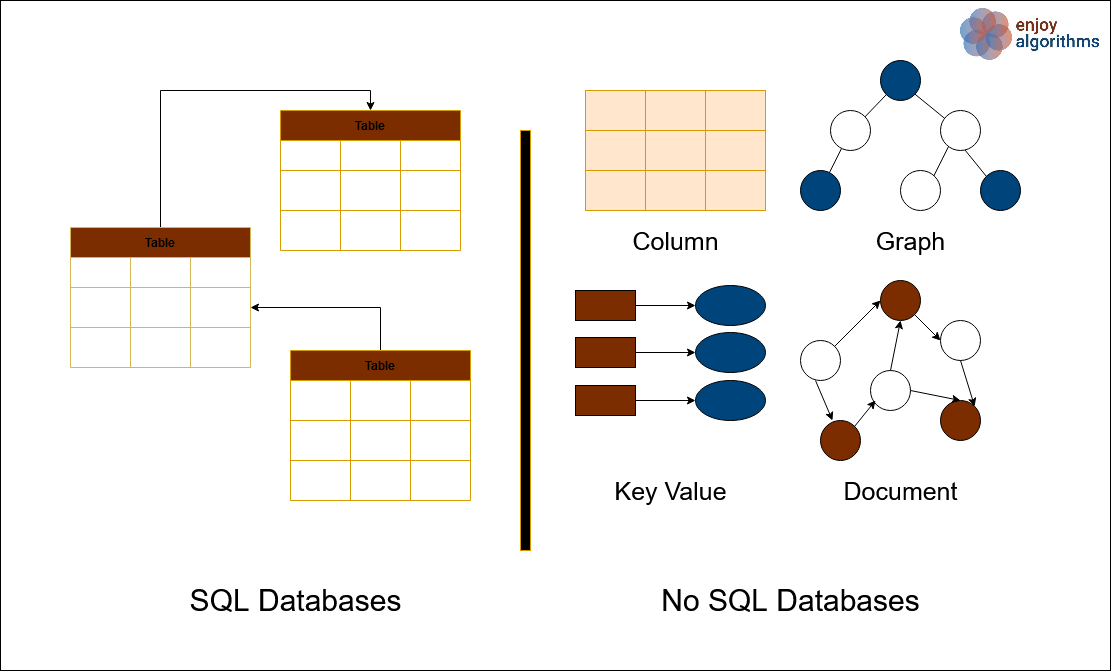
NoSQL databases embody diverse types, each tailored to specific facts models and use cases. Understanding the unique forms of NoSQL databases is important for choosing the most appropriate choice primarily based at the requirements of a particular software. Here are the primary varieties of NoSQL databases:
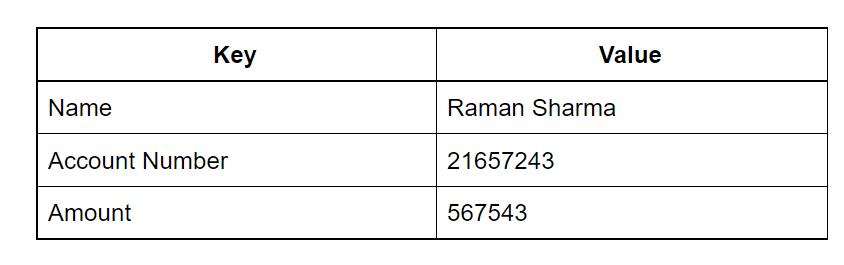
Key-Value Pair Databases:
- Description: Key-fee pair databases save facts as a collection of key-fee pairs, in which every information item is diagnosed via a completely unique key, and the related fee can be any facts type.
- Amazon DynamoDB is a key-cost controlled database provider that offers excessive scalability and low latency for applications requiring big records volumes and flexible information fashions.
- e.g. A gaming website that constantly updates the top 10 scores & players.
Document-Oriented Databases:
- Description: Document-orientated databases save records in files, normally in nested structures of keys and values. These databases allow for flexible schemas and retrieval of partial documents.
- Amazon DocumentDB (with MongoDB compatibility) is a specialised record database provider that permits storing and querying files with aid for secondary indexes and numerous records formats like JSON, BSON, and XML.
- e.g. A product evaluation website where 0 or many customers can review every product, and each review can be commented on with the aid of different customers and may be favored or disliked by means of zero to many customers.

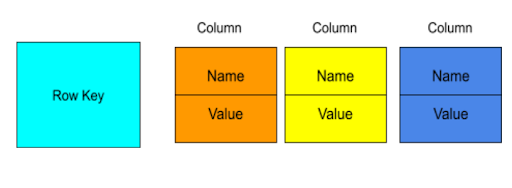
Wide-Column Databases:
- Description: Wide-column databases arrange information into column families, where every row is identified by using a unique row key, and columns are grouped primarily based on shared attributes. They offer scalability and versatility in coping with big quantities of facts.
- Amazon Keyspaces (for Apache Cassandra) is a wide-column controlled database provider that offers scalability and green storage for variable numbers of columns and a couple of statistics sorts.
- There are types:
- Standard Column : Standard Column includes a key-value pair, where the key’s mapped to a price that is a set of columns. In analogy with relational databases, a preferred column circle of relatives is as a “table”, each key-price pair being a “row”.
- Super Column : Super Column includes a key-cost pair, where the key’s mapped to a fee which are columns. In analogy with relational databases, a brilliant column circle of relatives is some thing like a “view” on some of tables. It also can be visible as a map of tables.
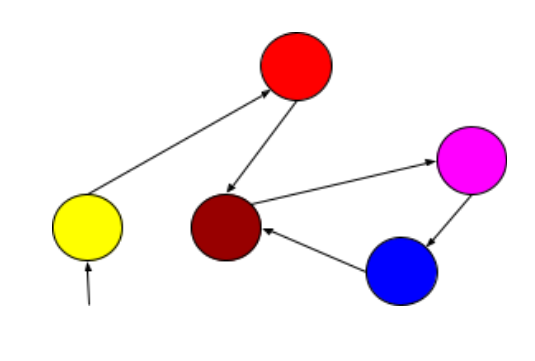
Graph Databases:
- Description: Graph databases are designed to shop quite related facts using entities (nodes) and relationships between them (edges). They excel in modeling complex relationships and traversing graph systems correctly.
- Amazon Neptune is a managed graph database provider that permits storing and querying graph facts with specialized question languages optimized for traversing graph structures.
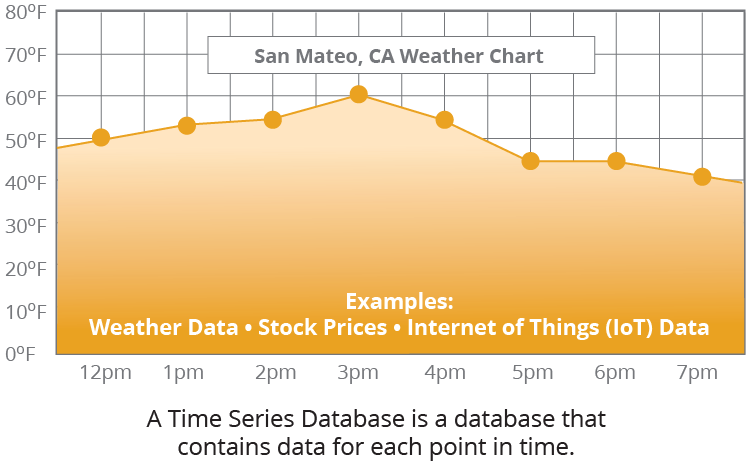
Time Series Databases:
- Description: Time collection databases are optimized for storing and retrieving time-sequenced records points associated with timestamps. They are ideal for applications requiring evaluation of time-based totally statistics like sensor readings or stock costs.
- Amazon Timestream is a controlled time collection database service that enables storing and studying time-sequenced statistics correctly.
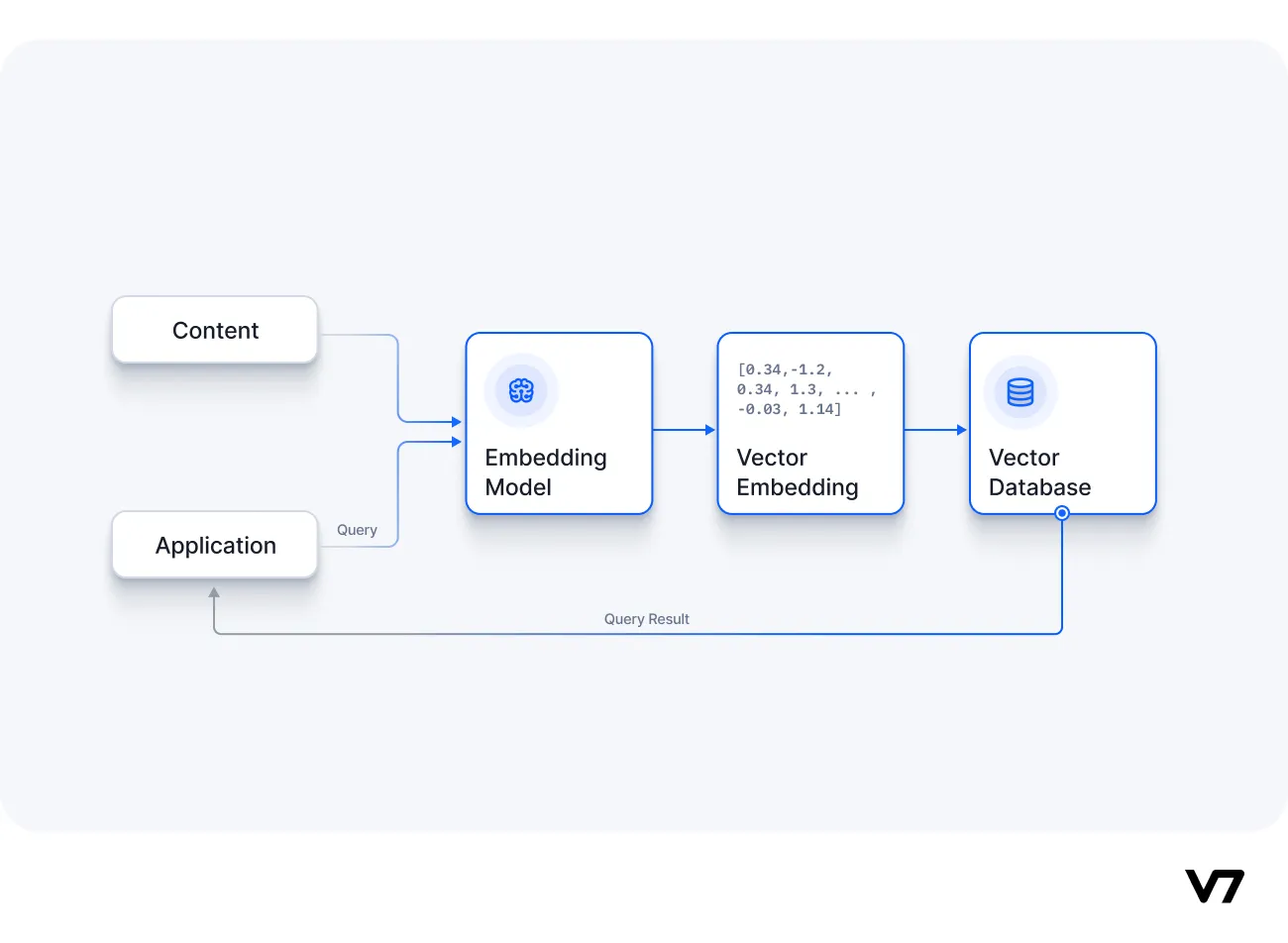
Vector Databases:
- Description: Vector databases are a specialised form of NoSQL database designed to handle vector facts, which are mathematical constructs that have each value and route. They are optimized for statistics parallelism, allowing them to procedure massive quantities of facts concurrently.
- Weaviate is an open-supply, cloud-local, real-time vector seek engine that permits users to keep, seek, and examine information within the form of vector embeddings.
- Vector embeddings are like digital fingerprints for phrases, sentences, or other styles of statistics. They turn complex facts into a chain of numbers that seize the essence of the records.
Therefore, each sort of NoSQL database is optimized for unique desires and use instances, supplying unique blessings in terms of scalability, flexibility, and data modeling. Understanding these sorts is important for choosing the most appropriate NoSQL database for your application’s necessities.
Reference:
Blaze Clan. (n.d.). Dive Deep: Types of NoSQL Databases. Blaze Clan. Retrieved March 25, 2024, from https://blazeclan.com/blog/dive-deep-types-nosql-databases/
Hazelcast. (n.d.). Time Series Database. Hazelcast. Retrieved March 25, 2024, from https://hazelcast.com/glossary/time-series-database/
Eckerson Group. (2023, May 10). The Why, What, Who, and Where of Vector Databases. Eckerson Group. Retrieved March 25, 2024, from https://www.eckerson.com/articles/the-why-what-who-and-where-of-vector-databases